
Analyses flow step 5: For further quantitative description of how gaze travels across the painting at individual and group level, we adopted methods of scan path comparison (summarised in Kübler 2016), dealing with data-specific biases in art-works, noisy measurements, subsequent visits to the same or nearby image regions, and reliance on a priori defined semantic regions of interest (ROIs). Our methods are based on classification of subsequence frequencies (‘Sally’: Rieck, Wressnegger, & Bikadorov, 2012) in longer transition sequences (such as exploring Pollock paintings) and used machine learning techniques to best discriminate the two paintings based on many combinations of sequence and sub-sequence transcriptions, thus going beyond Markov Chain models.
We implemented a standard technique for mapping strings to a vector space (‘bag-of-words model’). Number of letters (alphabet size A) correspond to ROIs, and letter sub-sequences to sparsely occurring events whose frequency is possible to count (n-gram of size N). In this model, a Markov chain is represented with N = 2, and is tested against many other combinations of A and N. Scan path are converted into their string representation, using a variety of algorithms to automatically determine amount of gaze assigned to probability bins (ROIs), which are then transcribed into letters as a function of A. We tested several automatic binning approaches, using (normalised) pixel coordinates of images to define borders of ROIs: distributing gaze data into equally sized bins (grid approach), or into probability chunks having equal amount of gaze assigned (percentile approach) or considering saccadic event amplitude.
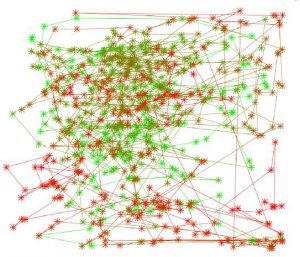
Normalised scan path reconstruction is used for automatic grid binning of eye movement data to determine ROIs (participant 11). Green: ‘Blue Poles’; Red: ‘Mural’
We implemented a standard technique for mapping strings to a vector space (‘bag-of-words model’). Number of letters (alphabet size A) correspond to ROIs, and letter sub-sequences to sparsely occurring events whose frequency is possible to count (n-gram of size N). In this model, a Markov chain is represented with N = 2, and is tested against many other combinations of A and N. Scan path are converted into their string representation, using a variety of algorithms to automatically determine amount of gaze assigned to probability bins (ROIs), which are then transcribed into letters as a function of A. We tested several automatic binning approaches, using (normalised) pixel coordinates of images to define borders of ROIs: distributing gaze data into equally sized bins (grid approach), or into probability chunks having equal amount of gaze assigned (percentile approach) or considering saccadic event amplitude.
After segmenting and transcribing data into string sequences, we trained Support Vector Machines (SVM) on pooled data using 10-fold cross-validation (10% of the data used for validation, 90% for training), using all combinations of A (2-26) and N (1-10) to discriminate between two Pollock paintings. The highest accuracy (87.5%) was achieved with A=8 and N=7 using the amplitude of saccadic events to define ROIs. The two paintings were best discriminated using remarkably long eye movements sequences (7-step) and 8 regions of interest. Correspondingly, using our data-driven definition of ROIs derived in analysis flow step 3 (Fixation Hotspot), the classifier was able to distinguish the two Pollock paintings based on triplet subsequence of eye movements (N=3) and 5 most visited ROIs (A=5): the accuracy of the classifier was approximately 80%. Our results suggest that in complex scenarios such as free viewing of abstract paintings for a prolonged time, Markov chain models (N = 2) do not perform as well as using extended n-gram sequence analysis.
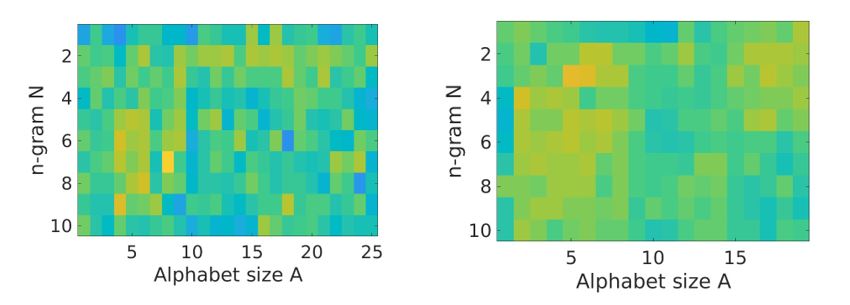
Discrimination performance of SVMs (in colour code, bright yellow patches indicating the highest accuracy of the classifier) to discriminate the two Pollock paintings, Left: using amplitude of saccadic events, and Right: using ‘Fixation Hotspot’, suggesting that longer eye movement are needed for good performance.